Logistic Regression
Function Set
- We want to find $P_{w,b}(C_1|x)$
- $P_{w, b}(C_1|x) = \sigma(z)$
- $ z = w \cdot x + b = \sum\limits_iw_ix_i + b $
- function set: $f_{w, b}(x) = P_{w, b}(C_1|x)$ // including all different w and b
Goodness of a Function
- 取minima的 对象写成一个function,这个function是
Cross entropy between two Bernoulli distribution - Cross Entropy: $H(p, q) = - \sum\limits_xp(x)ln(q(x))$
- cross entropy指的是p和q有多接近。如果p和q是一样的,则cross entropy等于0。

Logistic Regression vs Linear Regression
- 在function set上: Logistic比Linear在function上多一个sigmoid函数
- 在loss上,Logistic是所有$f(x^n)和\hat y^n的$cross entropy的总和
- 在作Gradient Disent时,function是一样的

Logistic Regression vs Linear Regression
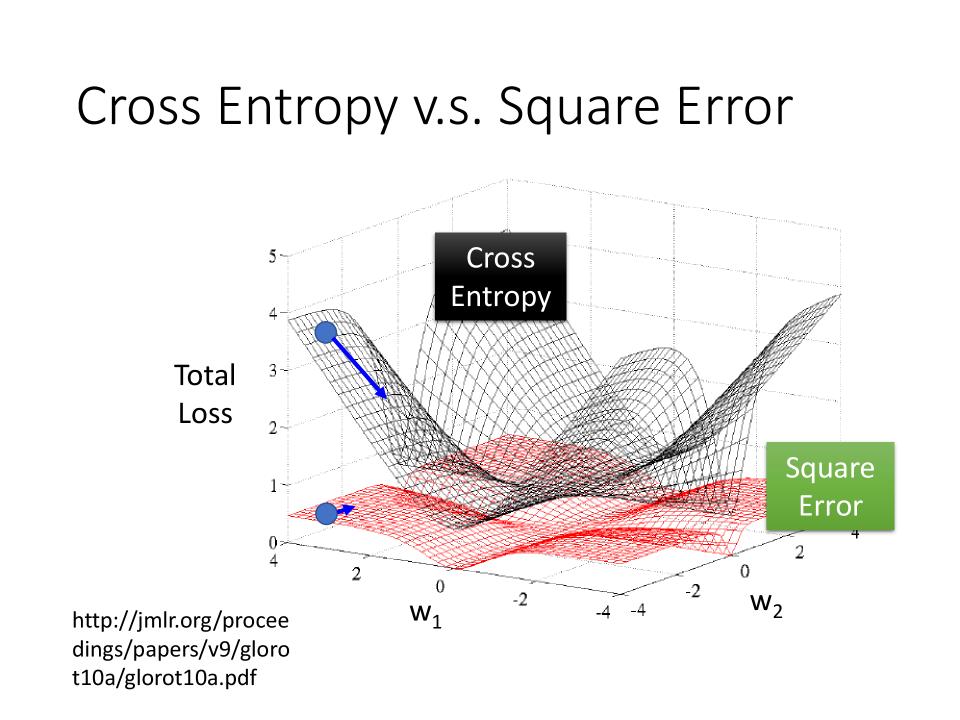
为什么Logistic Regression不能用Square Error作loss
- 参数的变化对Total Loss作图的话,黑色的是
Cross Entropy, 红色的是Square Error,如图 Cross Entropy在距离中心最佳点解越远时微分值越大,越近时越小- 而
Square Error无论距离中心最佳点远或者近,微分值都相对比较小。这样导致距离目标远时,参数update的很慢。
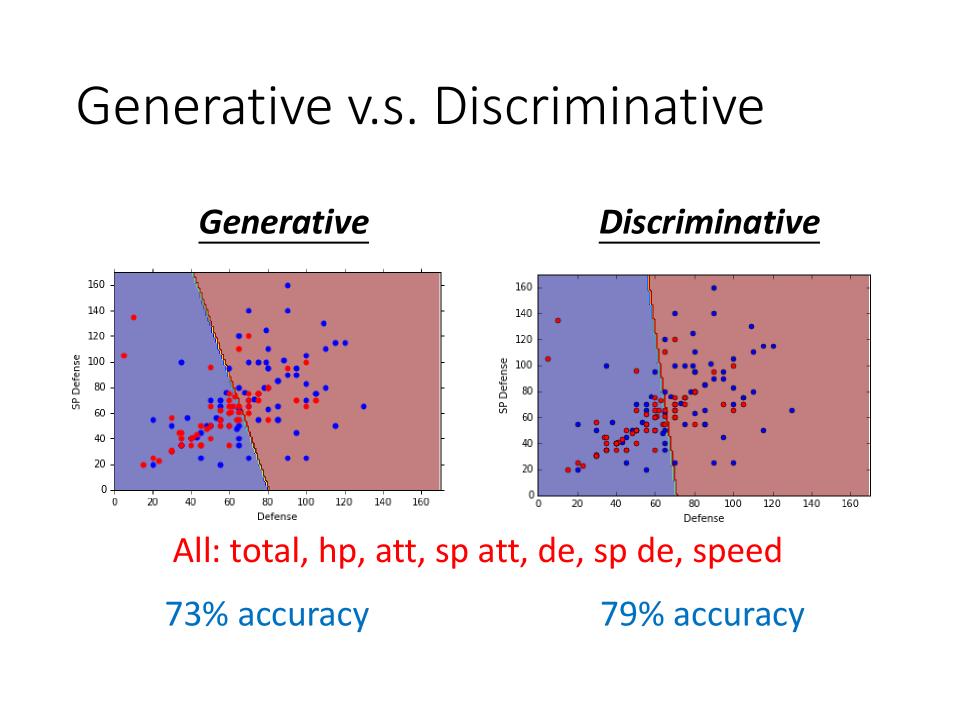
Discriminative v.s. Generative
- 他们的function set是一样的: $ P(C_1|x) = \sigma(w \cdot x +b) $
- 通常Discriminative的性能是强于Generative的,其原因主要是Generative的model是基于一些假设得到的。
- 不是所有情况下Discriminative的model都是强于Generative的
Benefit of generative model
- With the assumption of probability distribution, less training data is needed
- Discriminative的变化量受到data的变化量很大,随着数据越多,loss越小
- With the assumption of probability distribution, more robust to the noise
- 假设data中有一些noise,则Generative要强于Discriminative
- Priors and class-dependent probabilities can be estimated from different sources.
- 语音辨识中,Model是Generative的。
Multi-class Classification [Bishop, P209-210]
- softmax会强化大的值
- 从高斯分布推导后,可以得到这个softmax
- 使用softmax作为输出得到$y$,最好的target $\hat y$,则当target是one hot vector时,$y和\hat y$的 Cross Entropy的值最小

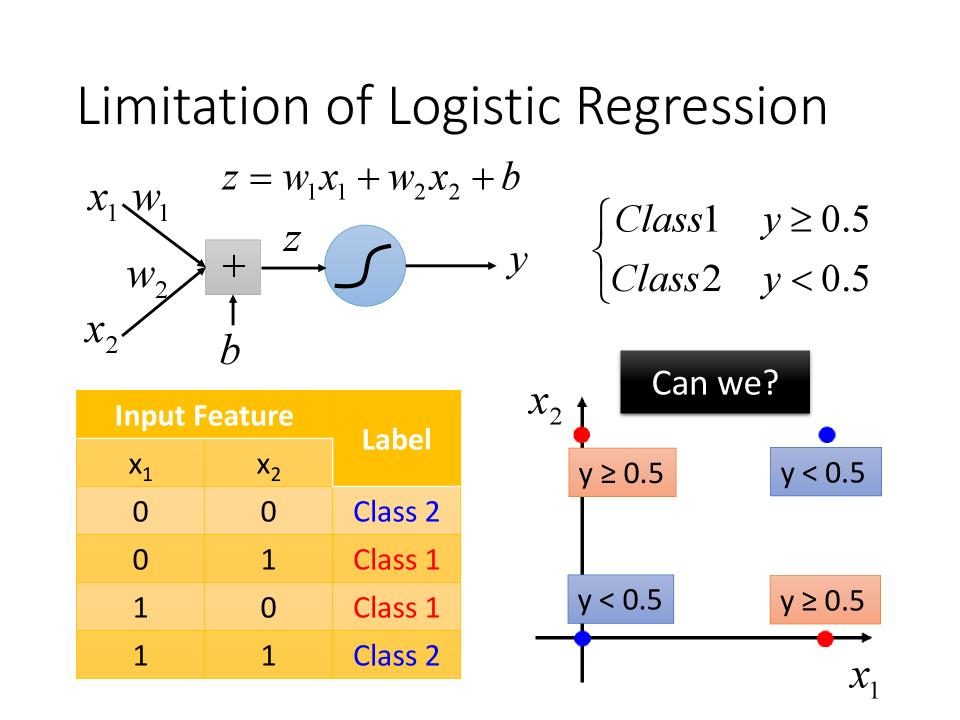
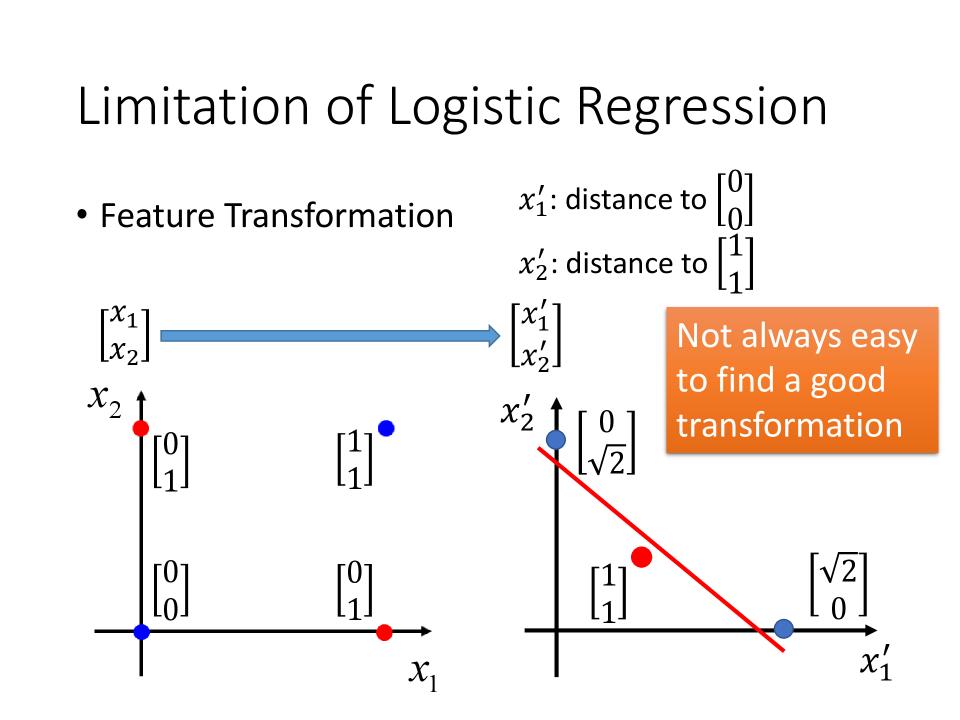
Limitation of Logistic Regression
- 如下图情况,无法找到一个函数将Class1和Class2很好的区分开
- 可以通过Feature Transformation的方式对feature作转换,然后对转换后的值进行分类
Feature Transformation
- 假设通过某种方式将$x_1, x_2$转化为$x_1^\prime, x_2^\prime$,如图右边,则可以找到一个函数,将class1和class2区分开来
- 那么如何让机器自己找到这种函数呢?
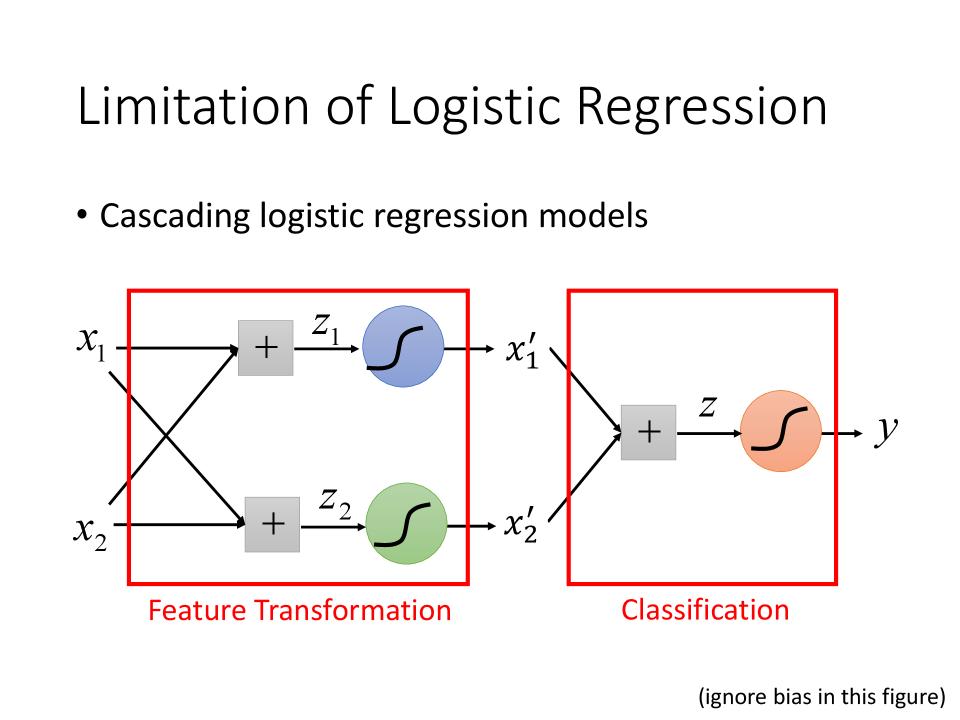
Cascading logistic regression models
- 如下图,前面的Logistic是Feature Transformation,后面的Logistic是Classification